
소켓(Socket)
소켓은 프로토콜, IP 주소, 포트 넘버로 구성되고, 프로세스가 데이터를 보내거나 받기 위한 창구 역할을 하는 존재임
전송 계층(Transport layer)와 프로세스 사이에서 인터페이스 역할을 하며 떨어져 있는 두 호스트를 연결하는 존재
소켓은 장치 파일의 일종으로 이해할 수 있음 / 일반 파일에 대한 개념이 대부분 적용됨
소켓 프로그래밍을 통해 네트워크 상의 다른 프로세스와 데이터를 주고 받을 수 있음
소켓의 3 요소
* 프로토콜
프로토콜은 원래 외교상의 언어로써 의례나 국가간에 약속을 의미하며, 통신에서는 어떤 시스템이 다른 시스템과 통신을 원활하게 수용하도록 해주는 통신 규약, 약속
* IP
전 세계 컴퓨터에 부여된 고유의 식별 주소
* 포트
포트(Port)는 네트워크 상에서 통신하기 위해서 호스트 내부적으로 프로세스가 할당받아야 하는 고유한 숫자
한 호스트 내에서 네트워크 통신을 하고 있는 프로세스를 식별하기 위해 사용되는 값이므로, 같은 호스트 내에서 서로 다른 프로세스가 같은 포트 넘버를 가질 수 없음
같은 컴퓨터 내에서 프로그램을 식별하는 번호
16 bits로 이루어진 숫자(0~65535)
- 0 ~ 1023 : well-known ports, system ports (ex : HTTP(80), HTTPS(443), DNS(53))
- 1024 ~ 49151 : registered ports (IANA(인터넷 할당번호 관리 기관)에 등록된 번호)(ex : MySQL DB(3306), Apache tomcat server(8080))
- 49152 ~ 65535 : dynamic ports (등록되지 않은 번호, 임시로 혹은 자동 할당될 때 사용)
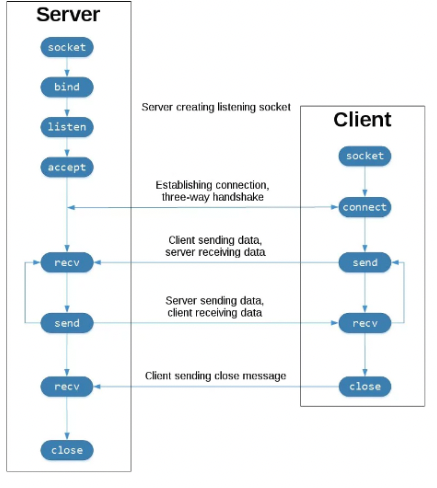
소켓 통신의 흐름

서버 (Server)
- socket() 함수를 이용하여 소켓을 생성
- bind() 함수로 ip와 port 번호를 설정
- listen() 함수로 클라이언트의 접근 요청에 수신 대기열을 만들어 몇 개의 클라이언트를 대기 시킬지 결정
- accept() 함수를 사용하여 클라이언트와의 연결을 기다림
- send(), recv() 함수로 데이터를 송수신함
- close() 함수로 소켓을 닫음
클라이언트 (Client)
- socket() 함수로 가장 먼저 소켓을 엶
- connect() 함수를 이용하여 통신 할 서버의 설정된 ip와 port 번호에 통신을 시도
- 통신을 시도 시, 서버가 accept() 함수를 이용하여 클라이언트의 socket descriptor를 반환
- 이를 통해 클라이언트와 서버가 서로 send(), recv()를 하며 통신 (이 과정이 반복)
- close() 함수로 소켓을 닫음
서버 소켓 프로그래밍(Server Socket Programming)
클라이언트 소켓을 처리하는 과정의 API는 비교적 간단하지만 서버 소켓의 경우 그 처리 과정이 조금 복잡합니다.
서버 소켓 생성(socket())
클라이언트 소켓과 마찬가지로 서버 소켓을 사용하려면 최초에 소켓을 생성해야 합니다.
서버 소켓 바인딩(bind())
bind의 사전적의미로 ‘결합하다’, ‘구속하다’, ‘묶다’등의 의미를 가지고 있습니다. bind() API에서 사용되는 인자는 두가지 소켓 과 포트번호(또는 IP+포트번호) 입니다. 즉 사전적 의미로 바라보면 소켓과 포트번호를 결합한다는 의미입니다.
보통 시스템에는 많은 수의 프로세스가 동작합니다. 만약 어떤 프로세스가 TCP 또는 UDP 프로토콜을 사용한다면 각 표준에 따라 소켓은 시스템이 관리하는 포트 중 하나의 포트 번호를 사용하게 됩니다. 그런데 만약 소켓이 사용하는 포트 번호가 다른 소켓의 포트 번호와 중복된다면 어떻게 될까요?
모든 소켓이 1000이라는 동일한 포트번호를 사용하게 된다면, 네트워크를 통해 1000번 포트로 어떤 데이터가 수신될 때 어떤 소켓으로 이를 처리해야할 지 결정할 수 없는 문제가 발생하게 될 것 입니다.
그렇기 때문에 운영체제에서는 소켓들이 중복된 포트번호를 사용하지 않게 하기 위해 내부적으로 포트번호화 소켓 연결정보를 관리합니다.
그리고 bind()API에서는 해당 소켓이 지정된 포트 번호를 사용할 것이라는 것을 운영체제에 요청하는 것이 바로 해당 API의 역할입니다. 만약 지정된 포트 번호를 다른 소켓이 사용하고 있다면 bind() API는 에러를 리턴합니다. 즉 일반적으로 서버 소켓은 고정된 포트번호를 사용합니다. 그리고 그 포트 번호를 통해 클라이언트의 연결 요청을 받아들입니다. 그리고 운영체제가 특정 포트 번호를 서버 소켓이 사용하도록 만들기 위해 소켓과 포트 번호를 결합하는데 이를 결합하기 위해 사용하는 API 가 바로 bind()인 것입니다.
이를 소켓바인드, 소켓 바인딩이라고도 부릅니다.
클라이언트 연결 요청 대기(listen())
서버 소켓에 포트번호를 결합하고 나면 서버 소켓을 통해 클라이언트 연결 요청을 받아들일 준비가 되고, 이제는 클라이언트에 의한 연결요청이 수신될 때까지 기다리게 됩니다. listen()API가 그 역할을 수행합니다.
서버 소켓에 바인딩된 포트 번호를 통해 클라이언트의 연결 요청이 있는지 확인하며 대기상태에 머물게 되고, 클라이언트에서 호출된 connect() API에의해 연결요청이 수신되는지 귀 기울이고 있다가 요청이 수신되면 그 때 대기 상태를 종료하고 결과를 리턴합니다. 이렇게 listen() API가 대기 상태에서 빠져나오는 경우는 크게 두가지 입니다.
- 클라이언트 요청이 수신되는 경우
- 에러가 발생하는 경우
그런데 listen()API가 성공한 경우라도 리턴 값에는 클라이언트 요청에 대한 정보는 들어있지 않는 것이 특징입니다. 이때 반환되는 리턴값에서 판단할 수 있는 것은 단 두가지로 연결 요청이 수신되었는지(success), 그렇지 않고 에러가 발생했는지(fail) 뿐입니다.
그리고 이 클라이언트 연결 요청에 대한 정보는 시스템 내부적으로 관리되는 큐(queue)에 쌓이게 되는데, 이 시점은 클라이언트와의 연결은 아직 완전히 연결된 상태라고는 할 수없는 여전한 대기상태임을 놓치지 말아야 합니다. 이렇게 대기 중이 연결 요청을 큐로부터 꺼내와서 연결을 완료하기 위해서는 accept()API를 호출해야합니다.
클라이언트 연결 수립(accept())
다시 한번, listen() API가 클라이언트 연결 요청을 확인하고 문제없이 리턴(success)한다고 해서, 클라이언트와의 연결 과정이 모두 완료된 것은 아닙니다. 아직 실질적인 소켓 연결(connection)을 수립하는 절차가 남아있습니다. 즉 최정적으로 연결 요청을 받아들이는 역할을 수행하는 것은 accept() API입니다.
연결 요청을 받아들여 소켓 간 연결을 수립하는 것이 바로 이 API의 역할입니다. 그런데 여기서 가장 중요한 점은 최종적으로 데이터 통신을 위해 연결되는 이 소켓은 앞서 bind(), listen() API에서 사용한 서버 소켓이 아니라는 점입니다. 즉, 클라이언트 소켓과 연결이 만들어지는 소켓은 앞서 사용했던 서버 소켓이 아닌 accept()API 내부에서 만들어진 새로운 소켓이라는 점 입니다.
서버 소켓의 핵심역할은 클라이언트의 연결 요청을 수신!하는 것입니다. 이를 위해 bind() 및 listen()을 통해 소켓에 포트번호를 바인딩하고 요청 대기 큐를 생성해 클라이언트의 요청을 대기하였죠. 그리고 이후 accept() API에서 데이터 송수신을 위한 새로운 소켓을 만들고 서버 소켓의 대기 큐에 쌓여있는 첫번째 연결요청을 매핑 시킵니다. 이렇게 하나의 연결 요청을 처리하기 위한 서버 소켓의 역할은 끝나게 됩니다.
데이터 송수신(send()/recv())
이제 실질적인 데이터 송수신은 accept()API에서 생성된 연결이 수립된(Establiched)된 소켓을 통해 처리 됩니다.
데이터를 송수신하는 과정은 클라이언트 소켓 처리 과정 내용과 동일합니다.
소켓 연결 종료(close())
클라이언트 소켓 처리 과정과 마찬가지로 소켓을 닫기 위해 close() API를 호출합니다.
그런데 서버 소켓에서는 close()의 대상이 하나만 있는것이 아니란 것이 중요합니다. 최초 socket() API를 통해 생성한 서커 소켓에 더해 accept() API 호출에 의해 생성된 소켓 또한 관리해야하기 때문이죠.
[출처]
https://www.zehye.kr/network/2021/10/23/Network_socket_http/
소켓 종류
스트림 소켓
- TCP(Transmission Control Protocol)을 사용하는 연결 지향방식의 소켓(연결 지향성)
- 양방향으로 바이트 스트림을 전송(바이트 스트림 : 큰 데이터를 잘게 쪼갠 뒤 전송하는 서비스)
- 오류 수정, 전송 처리, 흐름제어 보장
- 송신된 순서에 따라 중복되지 않게 데이터를 수신(신뢰성이 있음) → 오버헤드가 발생(시간적으로 오래 걸림)
- 소량의 데이터보다 대량의 데이터 전송에 적합
- 점대점 연결
데이터그램 소켓
- UDP(User Datagram Protocol)을 사용하는 비연결형 소켓(비연결형 소켓)
- 데이터의 크기에 제한이 있음
- 확실하게 전달이 보장되지 않음, 데이터가 손실돼도 오류가 발생하지 않음(100을 보냈는데 유실돼 80만 받을 수 있음)
- 실시간 멀티미디어 정보를 처리하기 위해 주로 사용 ex) 전화, 스트리밍 서비스
- 점대점 연결 뿐만 아니라 일대다 연결도 가능
- accept 과정없이 소켓 생성 후 바로 데이터 송수신

HTTP 통신과 SOCKET 통신의 비교
HTTP 통신
Client의 요청(Request)이 있을 때만 서버가 응답(Response)하여 해당 정보를 전송하고 곧바로 연결을 종료하는 방식
특징
- Client가 요청을 보내는 경우에만 Server가 응답하는 단방향 통신
- Server로부터 응답을 받은 후에는 연결이 바로 종료
- 실시간 연결이 아니고, 필요한 경우에만 Server로 요청을 보내는 상황에 유용
- 요청을 보내 Server의 응답을 기다리는 어플리케이션의 개발에 주로 사용
Socket 통신
Server와 Client가 특정 Port를 통해 실시간으로 양방향 통신을 하는 방식
특징
- Server와 Client가 계속 연결을 유지하는 양방향 통신
- Server와 Client가 실시간으로 데이터를 주고받는 상황이 필요한 경우에 사용
- 실시간 동영상 Streaming이나 온라인 게임 등과 같은 경우에 자주 사용
파일 디스크럽터(File Descriptor)
리눅스 혹은 유닉스 계열의 시스템에서 프로세스가 파일을 다룰 때 사용하는 것으로, 운영체제가 특정 파일에 할당해주는 정수 값
유닉스 시스템에서는 일반적인 파일부터 디렉토리, 소켓, 파이프, 블록 디바이스 등 모든 객체들을 파일로 관리하는데, 프로세스가 이 파일들을 접근할 때 파일 디스크럽터를 이용
응용 프로세스가 파일을 열거나 생성하게 되면 정수로된 파일 디스크립터를 얻게 되는데, 이 파일의 디스크립터는 이후에 일어나는 모든 파일 동작(읽기, 쓰기, 파일 동작제어, 파일 닫기) 등의 동작에서 그 파일을 가리키는데 사용(0, 1, 2는 기본적으로 할당되는 파일 디스크립터)
기본적으로 할당되는 파일 디스크립터
- 0 : 표준 입력(Standard Input) / STDIN_FILENO
- 1 : 표준 출력(Standard Output) / STDOUT_FILENO
- 2 : 표준 에러(Standard Error) / STDERR_FILENO
그러면 우리가 생성하는 파일 디스크립터는 3번부터 차례대로 할당받게 됨
파일 디스크립터는 파일을 다루기 위해서 해당 파일의 주소를 참조하여 접근하는 형태

- FD Table의 각 칸들은 FD Flag와 File Table Pointer를 가지고 있음
- File Table의 각 칸들은 mode와 inode Table Pointer의 Offset을 가지고 있음
- inode Table은 소유자 그룹, 접근 모드(읽기, 쓰기, 실행 권한), 파일 형태, 아이노드 숫자(inode number, i-number) 등 해당 파일에 관한 정보를 가지고 있음
- inode란?
파일을 기술하는 디스크 상의 데이터 구조로서 파일의 데이터 블록이 디스크 상의 어느 주소에 위치하고 있는가와 같은 파일에 대한 중요한 정보를 갖고 있음
각각의 inode들은 고유번호(inode number)를 가지고 있어서 파일을 식별할때 사용
터미널에서 ls -i 옵션으로 inode number를 확인할 수 있음
- inode란?
파일 디스크럽터 확인 코드
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
int main(void)
{
int fd;
fd = open("test.txt", O_RDONLY);
if (fd < 1)
{
printf("open() error");
exit(1);
}
printf("FD : %d\n", fd);
close(fd);
return (0);
}
실행 결과

파일 디스크럽터 복제 및 변경 코드
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
int main(void)
{
int fd;
int fd2;
fd = open("test.txt", O_RDONLY);
fd2 = open("test.txt", O_RDONLY);
if (fd < 1 || fd2 < 1)
{
printf("open() error");
exit(1);
}
printf("fd\t: %d\n", fd);
printf("fd2\t: %d\n", fd2);
printf("fd2 = dup(fd)\n");
fd2 = dup(fd);
printf("fd\t: %d\n", fd);
printf("fd2\t: %d\n", fd2);
close(fd);
close(fd2);
return (0);
}
/*
기존 fd는 3을, fd2는 4를 할당받았다.
이후 dup()함수를 활용해서 fd를 복사해서 fd2에 넣었더니 fd2가 5가 되었다.
이것은 3이 이미 사용중인 파일 디스크럽터이고 4도 지금 현재 fd2에서 사용중이므로 5번이 새로 할당된 것이다.
즉 dup()를 통해서 복제를 하면 새로운 파일 디스크립터를 생성한다고 생각하면 된다.
*/
실행 결과

CGI(Common Gateway Interface)
웹 서버와 외부 프로그램(웹 애플리케이션) 사이에서 정보를 주고받는 방법이나 규칙들
동적인 컨텐츠를 생성하기 위한 인터페이스


동작 방식
- 클라이언트가 웹 서버에 요청(HTTP 요청)을 보냄
- 웹 서버는 요청을 CGI 프로그램에 전달
- CGI 프로그램은 요청을 처리하고 결과를 생성
- CGI 프로그램은 생성된 결과를 웹 서버로 반환
- 웹 서버는 결과를 클라이언트에게 전송
CGI 프로그래밍
- CGI 프로그램은 다양한 언어(Perl, C/C++, Python, PHP 등)로 작성 가능
- 웹 서버와의 통신을 위해 표준 입출력(stdin, stdout, stderr)을 사용
- 환경 변수를 통해 요청 정보(HTTP 요청 방식, 쿼리 문자열 등)를 전달받음
장단점
장점
- 다양한 언어로 프로그래밍 가능(개발자가 익숙한 주로 스크립트 언어를 선택할 수 있어 생산성이 높아짐)
- 웹 서버와 독립적으로 실행되어 유연성 높음(서버와 별도의 프로세스로 실행)
단점
- 매 요청마다 새로운 프로세스를 생성하므로 오버헤드가 큼
- 동적 웹 애플리케이션에 적합하지 않음(매 요청마다 프로세스를 생성하기 때문에 상태 유지가 어려움)
웹 서버와 WAS
웹 서버(Web Server)
웹 서버는 클라이언트(사용자)가 브라우저 주소창에 url을 입력하여 어떤 페이지를 요청하면. HTTP 요청을 받아들여 HTML 문서와 같은 정적인 콘텐츠를 사용자에게 전달해주는 역할을 함
웹 서버의 대표적인 임무 2가지
- 단순히 저장된 웹 리소스들을 클라이언트로 전달하고, 클라이언트로부터 콘텐츠를 전달받아 저장하거나 처리
- 사용자로부터 동적인 요청이 들어왔을 때, 해당 요청을 웹 서버 자체적으로 처리하기 어렵기 때문에 WAS에게 요청
웹 서버는 정적 웹서버와 동적 웹서버로 나뉨
대표적인 웹서버로는 Apache HTTP Server, nginx가 있고, AS에는 Apache Tomcat
정적 웹 서버
- HTTP 서버가 있는 컴퓨터로 구성
- 서버에 존재하는 이미 저장된 파일(HTML, 스크립트 등)을 브라우저에게 전송
- 서버에 저장된 데이터가 변경되지 않는 한 고정된 웹 페이지를 보게 됨
동적 웹 서버
- 정적 웹 서버와 어플리케이션 서버(AS)로 구성
- AS는 웹 서버에서 처리하지 못하는 동적 데이터에 대응하기 위해 만들어진 어플리케이션 서버(데이터베이스 조회, 로직 처리 등)
- 어플리케이션 서버는 프로그램에게 응답을 전달 받아 웹 서버에 전달하게 됨
- WAS는 웹 서버 + 어플리케이션 서버를 포함하는 개념

WAS(Web Application Server)
웹 서버가 할 수 있는 기능 대부분을 WAS에서도 처리가 가능하며, 비지니스 로직(서버 사이드 코드)을 처리할 수 있어 사용자에게 동적인 콘텐츠를 전달할 수 있음
주요 임무는 동적인 요청을 받아 처리해주는 서버
대표적인 WAS의 종류는Tomcat, JBoss, Jeus, Web Sphere

웹 애플리케이션 서버(Web Application Server, WAS)는 웹 애플리케이션과 서버 환경을 만들어 동작시키는 기능을 제공하는 소프트웨어 프레임워크이다. 인터넷상에서 HTTP를 통해 사용자 컴퓨터나 장치에 애플리케이션을 수행해주는 미들웨어로 볼 수 있다. 웹 애플리케이션 서버는 동적 서버 콘텐츠를 수행하는 것으로 일반적인 웹 서버와 구별이 되며, 주로 데이터베이스 서버와 같이 수행된다. 영어권에서는 'Application Server(AS)'라고 부른다.
웹 서버와 WAS 차이점
- 웹 서버는 정적인 데이터를 처리하는 서버 -> WAS만을 이용하는 경우보다 빠르고 안정적으로 기능을 수행
- WAS는 동적인 데이터를 위주로 처리하는 서버 -> DB와 연결되어 사용자와 데이터를 주고 받으며, 조작이 필요한 경우 WAS 활용
효율적 사용
- 정적인 콘텐츠만을 제공하는 웹 사이트를 서버에 배포한다면 웹 서버만으로도 충분함
- 하지만 동적인 컨텐츠를 제공해야하는 웹 서비스 배포를 해야한다고 하면, 정적 + 동적 요청 처리가 모두 가능한 WAS로 처리해도 되는 것 아닌가 하는 생각이 듬
- WAS에게 정적 콘텐츠 요청까지 처리하게 된다면, 부하가 커지고 동적 컨텐츠 처리가 지연되면서 수행 속도가 느려지고 이에 따라 페이지 노출 시간이 늘어나는 문제가 발생해 효율성이 크게 떨어짐


MIME Type(Media Type)
인터넷에 전달되는 파일 포맷 및 포맷 컨텐츠를 위한 식별자
IANA에서 이를 표준화하고 출판하는 공식 기관으로서의 역할을 하고 있음(IANA : 인터넷 할당번호 관리 기관)
구조
- 기본 : type/subtype 구조
- type은 파일의 종류를 의미하며, subtype은 파일의 포맷을 의미
- application/json의 경우, 바이너리 파일(application) 중 json 포맷의 파일을 의미하는 식별자로서 기능
- 추가 세부정보를 보내기 위해 파라미터를 사용할 수 있음
- 웹이 점차 보편화 되면서 MIME type 또한 Media type 이라는 이름으로 확장
[type]/[subtype];[parameter=value]
text/plain;charset=us-ascii
type의 종류
- discrete : (개별) 타입은 IANA에서 지정한 단일 문서의 카테고리
- text : 텍스트를 포함하는 모든 문서 [plain, html, css, javascript]
- image : 모든 종류의 이미지 파일 [gif, png, jpeg, bmp, webp]
- audio : 모든 종류의 오디오 파일 [midi, webm, ogg, wav]
- video : 모든 종류의 비디오 파일 [webm, ogg]
- model : 3D 오브젝트 관련 모델 데이터 [3mf, vrml]
- font : 모든 종류의 폰트 데이터 [woff, ttf, otf]
- application : 모든 종류의 바이너리 데이터 [pdf, json, octet-stream]
- multipart : 다른 MIME type을 지닌 메세지들로 이루어진 하나의 복합적인 메세지
- form-data
- mixed
- alternative
Content-type
- 웹 서버에서 HTTP 통신을 통해 전달받은 요청의 Header 내에서, 해당 요청의 Body에 든 데이터 타입에 대한 정보를 나타냄
- Request Body에 들어가는 데이터 타입을 HTTP Header가 명시할 수 있는데, 이때 사용하는 필드를 Content-type
- MIME 표준 헤더 필드에 담긴 Content-type 과의 맥락은 다르지만, 사용 용도는 어느 정도 일맥상통함
MIME type과 Content-type의 다른 점
- Content-type 과 MIME type 의 목적성은 데이터의 타입을 명시하는 것
- 하지만 Content-type 의 경우 단순히 웹에 국한되어 사용되지만, MIME type 의 경우 인터넷 프로토콜에서 사용되므로 더 상위의 개념
- 한마디로, HTTP Request의 Header에 있는 Content-type 필드에는 Request Body에 담긴 데이터의 MIME type을 추가한다고 이야기함
multipart
- HTTP Request의 Header 필드인Content-type 에 multipart 타입이 들어왔다면, 이는 Body에 여러 종류의 단일 데이터가 결합된 형태의 데이터가 존재한다는 의미
[도움되는 사이트]
'크래프톤 정글 - TIL' 카테고리의 다른 글
| 크래프톤 정글 5기 TIL - Day 46 (2) | 2024.05.04 |
|---|---|
| 크래프톤 정글 5기 TIL - Day 45 (0) | 2024.05.03 |
| 크래프톤 정글 5기 TIL - Day 43 (0) | 2024.05.02 |
| 크래프톤 정글 5기 TIL - Day 42(키워드 정리) (1) | 2024.05.01 |
| 크래프톤 정글 5기 TIL - Day 39 ~ 41 (0) | 2024.04.29 |